前段时间在面试快手的时候,遇到这样一个问题,JDK1.8之后ConcurrentHashMap为什么使用synchronized而不用lock。
当时是怎么胡驺的
当时遇到这个问题是懵逼的,一阵头脑风暴之后瞎蒙了3个原因
synchronized是Java的同步原语,可能性能上高过lock
唯一还靠谱点的猜测,然而经简单测试貌似在高并发的情况下反而是lock的性能要优于synchronized
ConcurrentHashMap出现的时候还没有lock,只能使用synchronized
一看就是阅读源码不仔细,ReentrantLock的源码上已经注明了 @since 1.5
lock是一个接口,从扩展性的角度来说不确定之后版本的实现类
纯属瞎蒙
书归正传
面完之后在网上搜了一下没找到相关问题,于是只能继续展开头脑风暴并得出一个自认为还算靠谱点的结论
以下解释仅代表个人观点非官方,欢迎交流讨论,若各位大佬有权威的解释也欢迎直接拍过来
既然使用的是synchronized而不是lock,自然有其道理在里面,比较了一下二者的优缺点感觉synchronized唯一的优点可能就是代码简洁,不需要像lock一样去手动释放。如果只因为这一个原因的话Doug Lea大神会差这点代码量?
我们都知道1.8之后ConcurrentHashMap是通过锁Node数组的头节点来缩小并发的粒度,如果说真的用lock来替换的话需要怎么做呢?这个问题粗看起来好像不是一个问题,当时面试的时候也是下意识的就避过了这个问题直到今天认真思考一番后发现,如果真的用lock实现好像很”麻烦“
首先,我们说默认的ReentrantLock,它的使用方式是通过lock.lock()来访问并发代码块,它没有lock.lock(param)这样的方法来锁定某个参数,既然如此先不管怎么实现,它的实现方式肯定就没有synchronized(f){}这样来的简洁。
其次,先不管简不简洁的问题,如果继续使用lock的话,这个lock要放到哪个类下呢?这里自然而然先想到是放在ConcurrentHashMap类里做为一个成员变量存在,如果真的这么做的话,锁的粒度还是一个Node节点吗?貌似常规使用的话这里锁住的是整个put()方法。
ok,那不放到ConcurrentHashMap下就只能放到Node节点中去了,事实上1.7版本的ConcurrentHashMap也正是这么做的,只不过它的实现方式是让Segment内部类去继承ReentrantLock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| static final class Segment<K,V> extends ReentrantLock implements Serializable {
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
transient volatile HashEntry<K, V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
Segment(float lf, int threshold, HashEntry<K, V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
}
|
既然1.8通过Node[]替换了Segment,那么如果沿用lock的话就是要么让Node去继承ReentrantLock,或者干脆在Node中定义成员变量lock。
这个时候继续考虑1.8的锁逻辑,ConcurrentHashMap通过lock来锁住Node数组的头节点,既然锁的是头节点,那该头节点所在链的其余Node节点自然就不需要进行加锁控制,可是lock已然成为了Node的属性那么对于链上的其余节点来说,这个lock就是被浪费掉了,因为只有在头节点被remove掉的时候其余Node节点才有可能会用上该成员变量(即只有原头节点的next节点)。这中间编码方面来说还需要考虑锁的“交接”等问题。
其实最开始思考这个问题的时候想到的是下文扩展里的内容,但是分析不下去了换了个思维想到了上述原因。感觉扩展的部分可能也是原因之一但再往底层这两者对ConcurrentHashMap的影响分析不出来了,不知道有没有熟悉的小伙伴可以解答一二。
总结
总结一下从编码角度来说,复杂度上升一个量级。又因为多引用了一个变量从资源角度来说会占用更多的资源。同时多引入的变量还是一个只针对头节点的一个变量。
以上,即是我对这个问题的思考。感觉很多“司空见惯”的场景仔细品一下还是有很多的乐趣在里面的
扩展
其实lock和synchronized除了网上说的是否公平、是否响应中断、是否支持绑定多个条件事件、是否需要手动释放锁资源外还有一个不同点。先说结论就是使用lock的时候线程处于waiting状态,而使用synchronized的时候处于blocked状态
下面是分别使用lock和synchronized来实现的死锁demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| public static void deadLockBySynchronized(){
final Object o1 = new Object();
final Object o2 = new Object();
ExecutorService threadPool = Executors.newFixedThreadPool(2);
threadPool.submit(new Runnable() {
@Override
public void run() {
synchronized (o1){
System.out.println("synchronized===thread:=="+Thread.currentThread()+"拿到o1资源");
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (o2){
System.out.println("thread:=="+Thread.currentThread()+"拿到o2资源");
}
}
}
});
threadPool.submit(new Runnable() {
@Override
public void run() {
synchronized (o2){
System.out.println("synchronized===thread:=="+Thread.currentThread()+"拿到o2资源");
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (o1){
System.out.println("thread:=="+Thread.currentThread()+"拿到o1资源");
}
}
}
});
threadPool.shutdown();
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| public static void deadLockByLock(){
final Lock lock1 = new ReentrantLock();
final Lock lock2 = new ReentrantLock();
ExecutorService threadPool = Executors.newFixedThreadPool(2);
threadPool.submit(new Runnable() {
@Override
public void run() {
lock1.lock();
System.out.println("lock===thread:=="+Thread.currentThread()+"拿到o1资源");
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock2.lock();
System.out.println("lock:=="+Thread.currentThread()+"拿到o2资源");
}
});
threadPool.submit(new Runnable() {
@Override
public void run() {
lock2.lock();
System.out.println("lock===thread:=="+Thread.currentThread()+"拿到o2资源");
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock1.lock();
System.out.println("lock:=="+Thread.currentThread()+"拿到o1资源");
}
});
threadPool.shutdown();
}
|
main方法如下
1
2
3
4
| public static void main(String[] args) throws Exception{
deadLockBySynchronized();
deadLockByLock();
}
|
既然是死锁其输出也没得啥悬念
1
2
3
4
| synchronized===thread:==Thread[pool-1-thread-1,5,main]拿到o1资源
synchronized===thread:==Thread[pool-1-thread-2,5,main]拿到o2资源
lock===thread:==Thread[pool-2-thread-1,5,main]拿到o1资源
lock===thread:==Thread[pool-2-thread-2,5,main]拿到o2资源
|
这个时候通过jstack来分析当前堆栈信息会发现一个有意思的现象
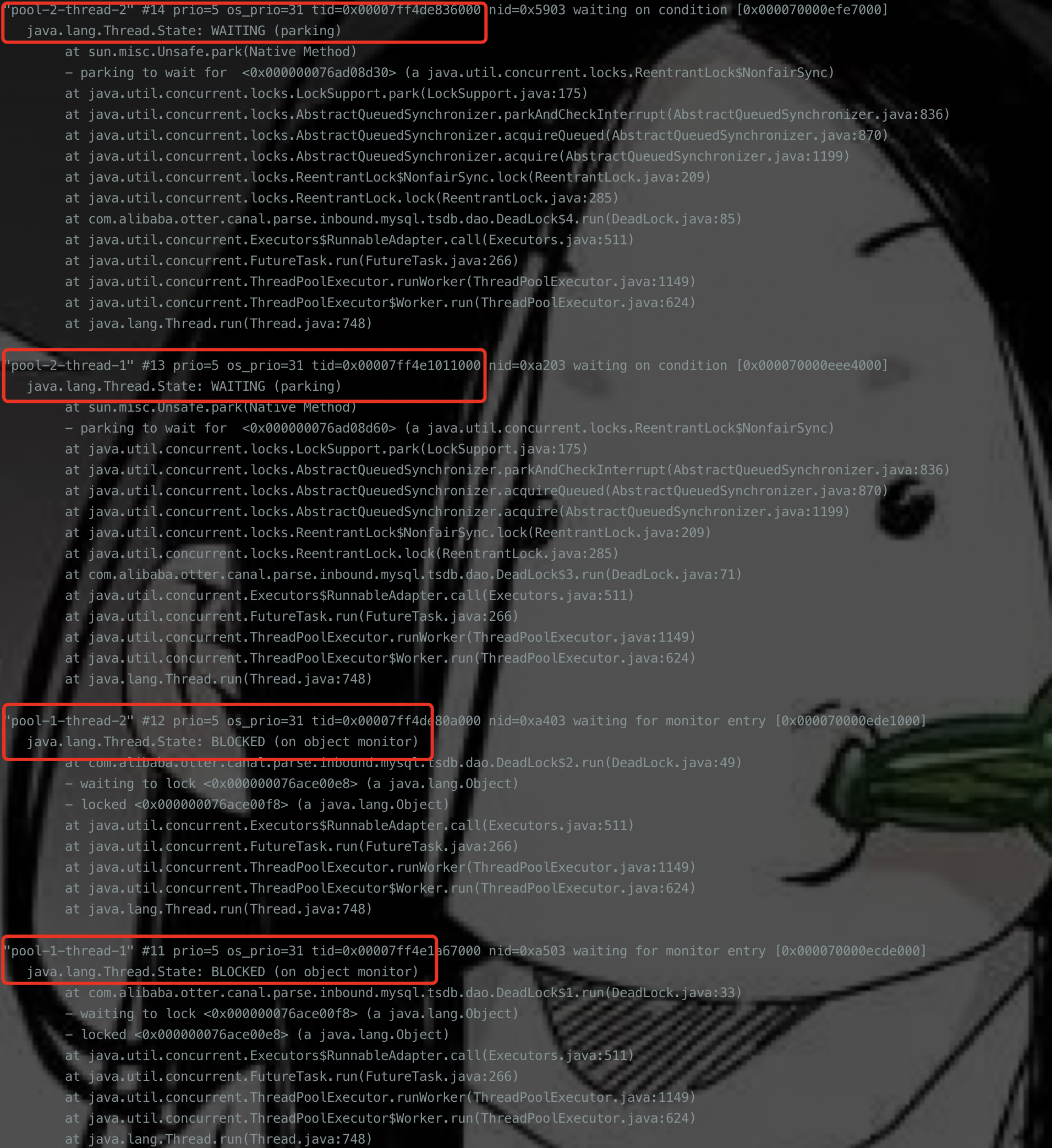
从图中可以清晰的看到,使用lock的时候线程处于waiting状态,而使用synchronized的时候处于blocked状态。至于二者的区别 百度一下 你就知道
TODO 猜测alibaba的Arthas的thread -b命令不适配lock也是基于这样的原因,回头翻翻源码确认一下