记一次Caffeine的惨案
Caffeine相信不少同学都有使用过,其优点及一些特性网上也有很多优质的文章,这里就不再赘述。(OS:当然,我也没去钻研)
这里举一个很简单的例子
1 | |
如上,当我们业务上使用cache#get(k)时,若入参k未命中本地缓存,则会调用CacheLoader的load方法进行加载并将对应的kv缓存到本地缓存中。其中load方法内部一般是一些数据装载方法,如从db、reidis中甚至是调用下游rpc查询数据,而后可能还包括一些数据组装。
如果我们使用Caffeine后,则会将将对应的值缓存到本地缓存中。提高我们系统的吞吐率同时减轻下游的负载。
1个实际的场景
设想这样一个需求场景。一个toC的系统中,我们需要针对部分白名单用户进行一些特殊的加权逻辑。对应的加权系数是存储在redis中。
方案一:不使用本地缓存直接从redis中查询
这样带来的问题就是,我们其实只需要对很小搓的白名单用户进行操作,这样如果所有请求都直接请求redis的话,redis的命中率会很低。且这部分白名单用户可能一直都不访问app,也就是说这些请求可能都是无效请求。
方案二:使用本地缓存,缓存的key就是用户的uid
这样的方式,虽然引入了本地缓存,但同理方案一,本地缓存的命中率也极低,所有的请求下钻到load方法取请求redis。属于吃力不讨好行为。
方案三:使用本地缓存,缓存的key是一个固定的常量
由于是白名单用户,本身规模不会特别大。这种方式相当于1次load方法将全部白名单及其对应的加权系数全部加载到本地缓存中。缓存的value不是具体的系数而是一个Map,Map的key是uid,value是加权系数。
这样方式优势是真实减少了对下游的请求量。劣势是会有一定的延迟性,及对白名单用户的更新不能及时的同步到真实线上。
由于我们评估了这个延迟可以接受,因此最终选择了方案三。
即使用本地缓存,且本地缓存的key是一个定值。Caffeine的load方法形似上述demo直接return一个公用方法
到这里暂停几分钟,请思考这种方式,有风险吗?
结论
我这么问,那就肯定是有风险的,这也是这篇文章的由来。
直接上结论,当load方法未正常return且高并发场景下,会造成业务线程阻塞,系统开始❌拒绝请求。整体服务出现不可用。
这里有两个关键的触发点:
- 高并发
- load方法未正常return,比如load方法内部出现了异常却没有捕获然后返回一个兜底值。
现象
说完结论,我们来贴图印证一下
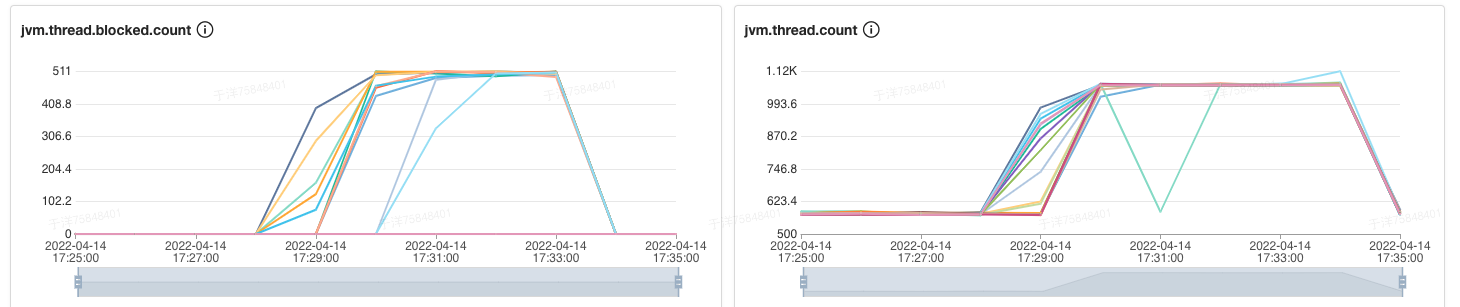
如图1可以看到,系统在大概17:28分blocked数开始升高。由于大部分线程处于blocked状态,导致整体可用线程减少,系统开始拒绝响应。
ok,我们来看一下,线程都阻塞在哪?
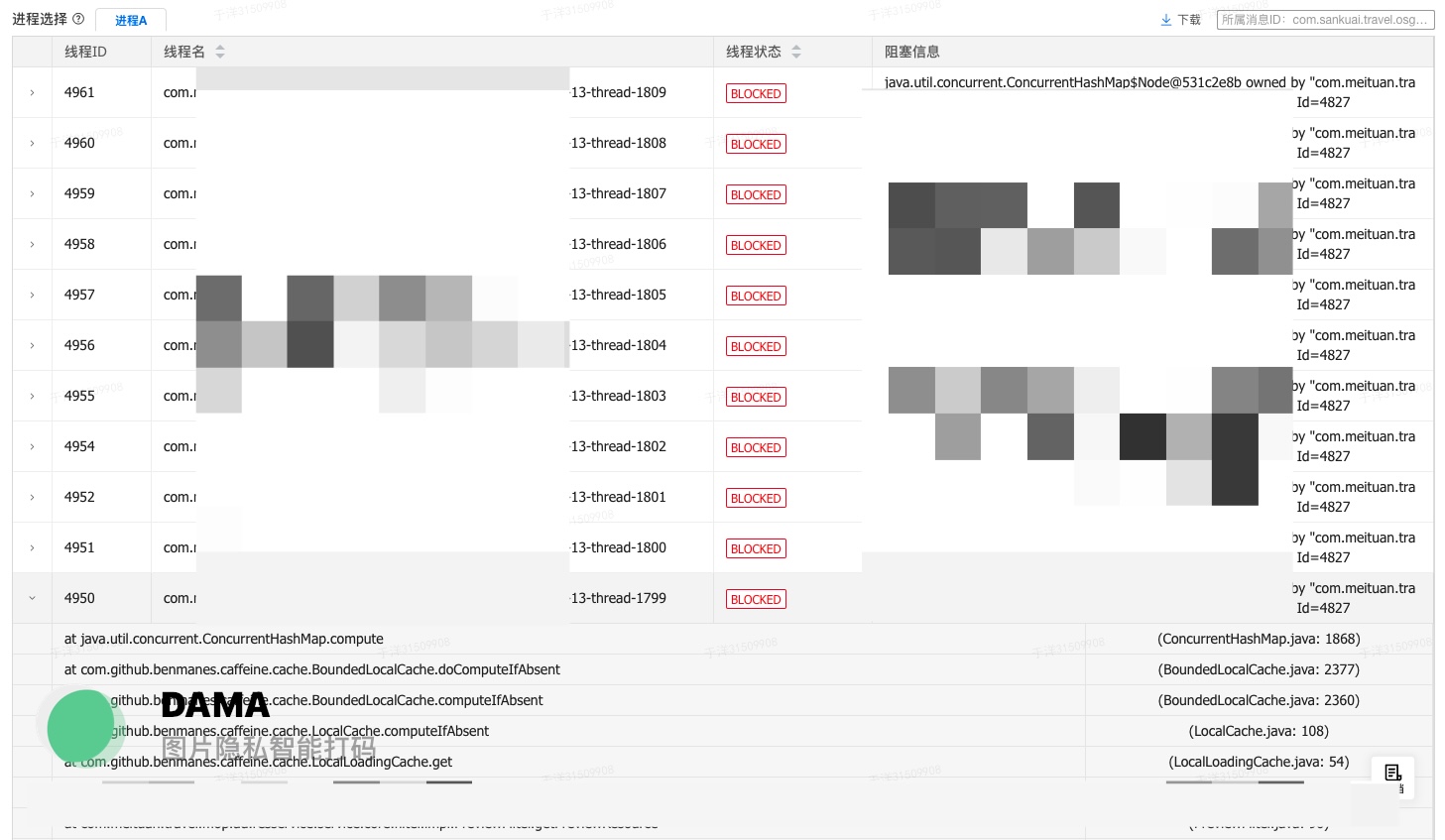
从图2的堆栈情况,不难看出线程block在ConcurrentHashMap#compute方法。
且都被在block在线程id=4827的线程。那么我们看一下4827这个线程在干嘛?
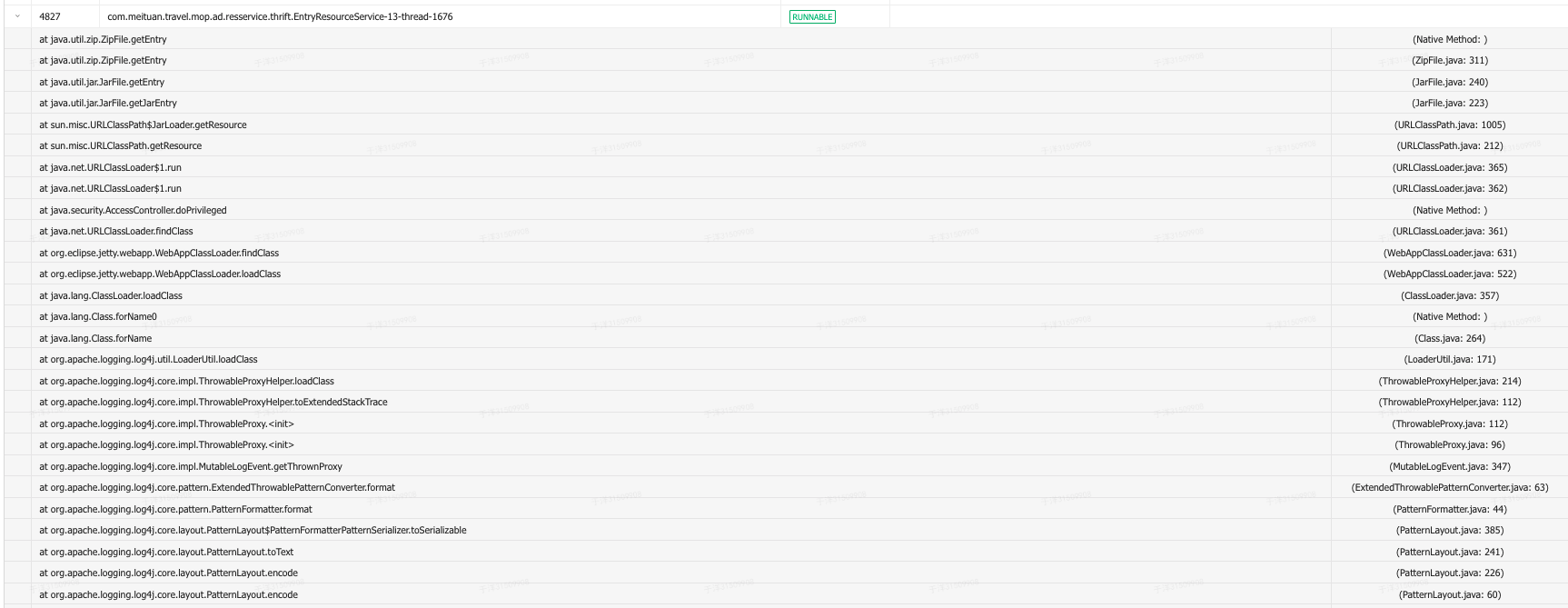
图3的堆栈情况来看,线程id=4827的线程正在runnable,且正在打印日志。
问题是,打印日志而已,又不是什么长耗时操作,怎么会block线程呢?被blocked的线程又被block在哪呢?
分析
由上图2的事故线程堆栈截图来看,线程阻塞在ConcurrentHashMap#compute方法的1868行,那么L1868到底是啥呢?
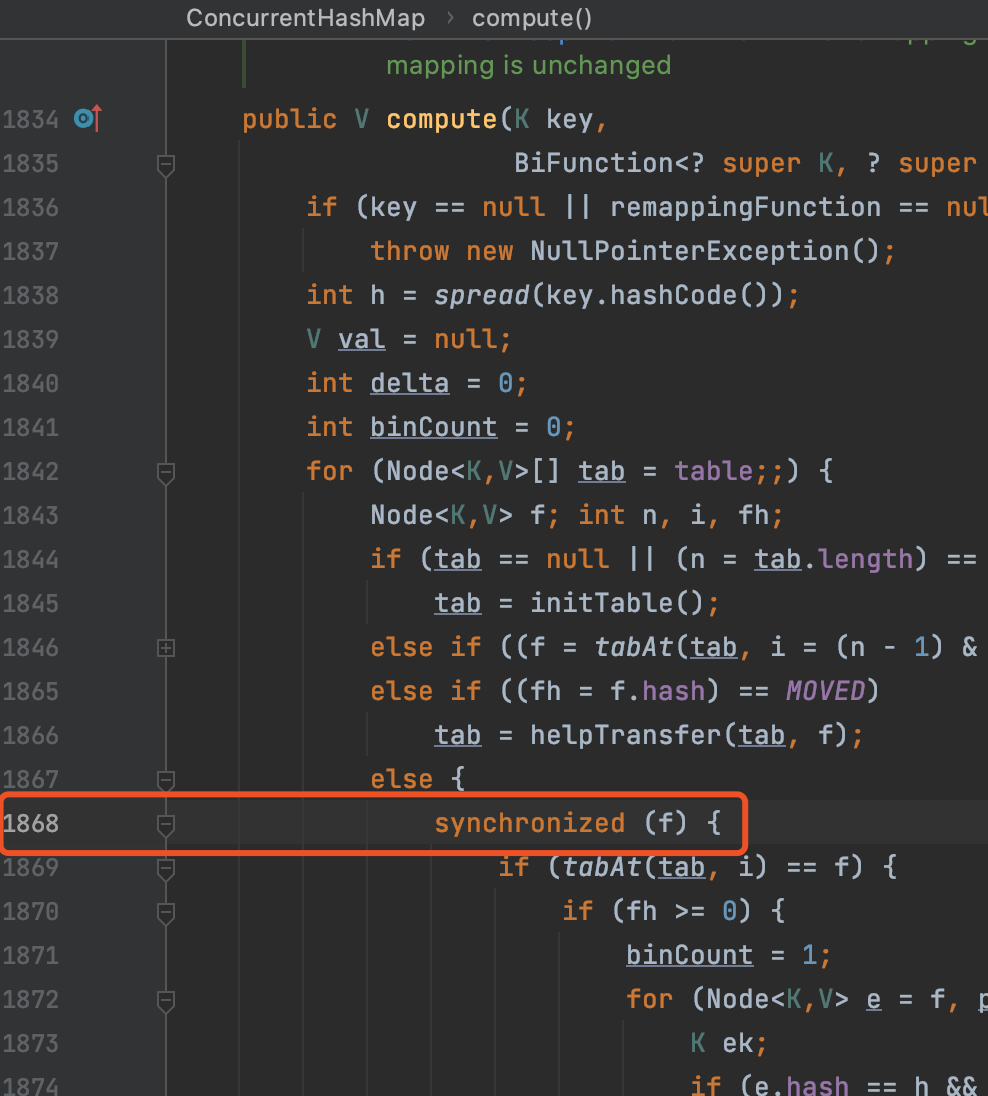
我们知道,ConcurrentHashMap是分段锁,每次写操作时,都会对入参key取hash然后对hash后的Node进行加锁。将锁从整个map下钻到具体的头节点上,降低锁冲突概率。
而上图3可以发现,L1868正是通过synchronized原语阻塞Node节点。也就是虽然使用了分段锁,但是锁冲突还是出现了。
那么我们只是使用了Caffeine#get方法,为啥会产生锁冲突呢?
要分析这个,不得不去扒一扒Caffeine的源码,这里我们只截取几个片段,毕竟本文不是Caffeine源码解析 ^.^
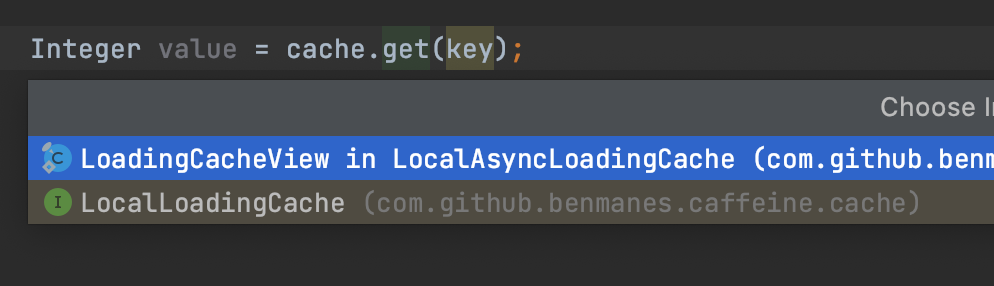
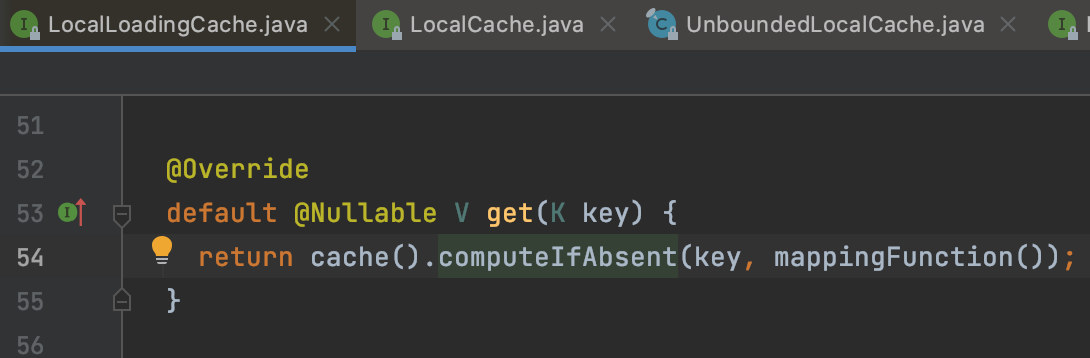
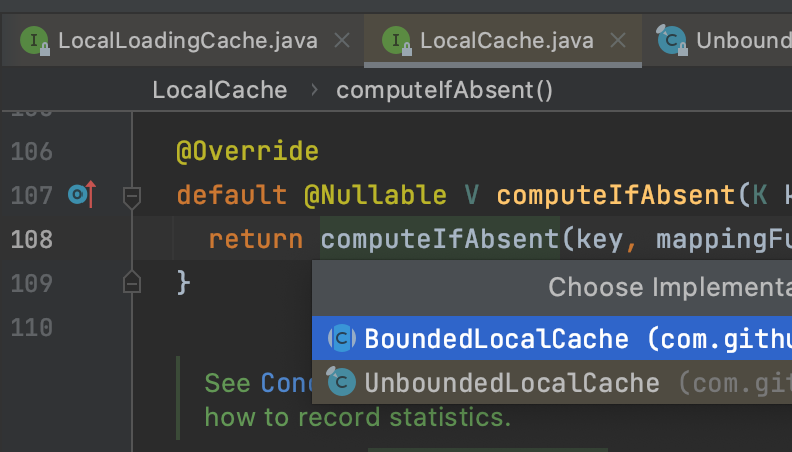
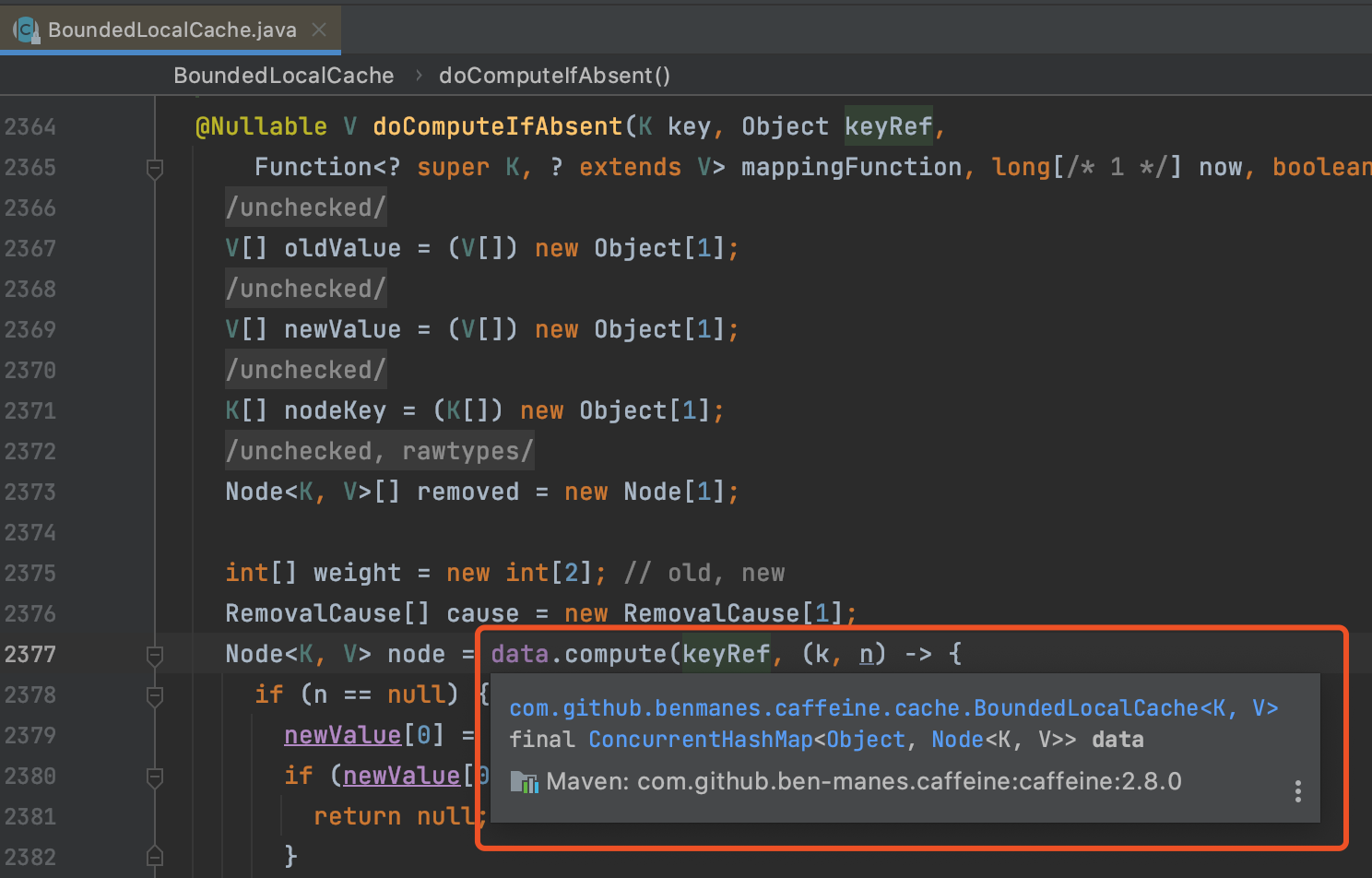
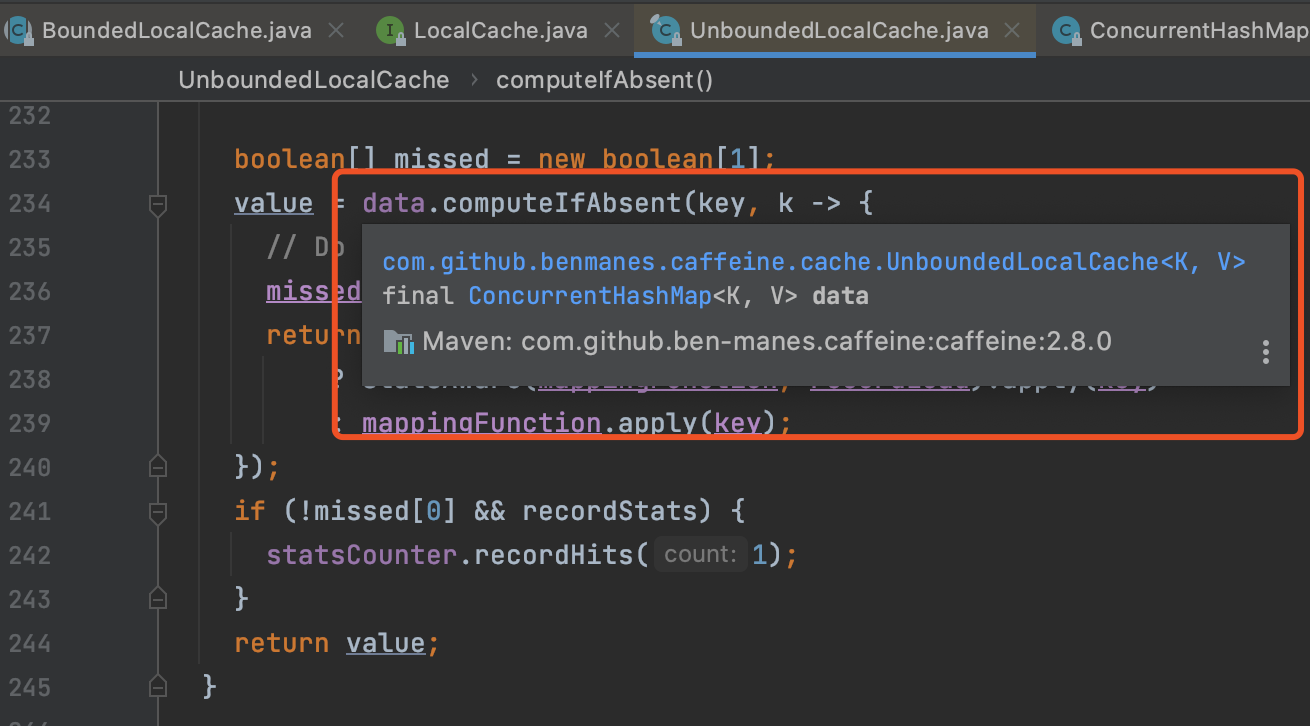
通过图4的LoadingCache#get方法我们发现一步步会来到图6的LocalCache#computeIfAbsent()方法,computeIfAbsent方法分别被LocalCache的两个实现类BoundedLocalCache/UnBoundedLocalCache实现。而无论是有界/无界的LocalCache,其都有一个类型是ConcurrentHashMap的一个变量,且他俩自定义实现的computeIfAbsent方法最终也会调用的这个类型为ConcurrentHashMap的成员变量的compute方法上。如图7、图8
总结
至此我们发现,当本地缓存未命中时,会调用LocalCache#computeIfAbsent方法进行数据的加载,而该computeIfAbsent的入参function即buildCache时传入的CacheLoader的load方法。
而在加载的时候,会通过ConcurrentHashMap阻塞该key对应的Node节点。
这就回到了本文开头。那么当本地缓存使用一个常量时,那么其经过hash后的Node节点也势必是同一个节点。这样每次synchronized也就会阻塞在同一个节点上。
然后,如果此时你的系统是一个高并发的系统,当其中1个线程在调用get方法缓存未命中时,就会阻塞调用load方法进行缓存填充。此时当缓存值未填充完时,其余请求都会被阻塞住。
但其实到这,其实还只是一个短暂的阻塞调用,毕竟load方法最终会成功返回一个值,而后的请求也将正常,整体服务并不会hang住。
but,若load方法异常了呢?且该异常未被try/cache,load方法也没有返回一个默认值。那么此时,由于load方法未返回一个兜底值,之后的所有请求都将缓存未命中,也都会阻塞调用CacheLoader#load方法,而又由于key相同所以阻塞在同一个节点上。高并发时,当load方法的响应速度超过入参请求数时,最终block的线程越来越多,可用线程越来越少。最终集群拒绝请求。
最佳实践
那么有没有最佳实践呢?
私以为可以通过如下几个方式去解决
- 在Caffeine的使用过程中,尽可能避免使用同一个key值的场景
- 若无法避免同一个key,需做好压测,评估系统的qps是否足以发生线程block情况
- 需要评估本地缓存若返回默认值是否有业务上的影响,若没有则load方法内部需要try/cache,保证即使load方法内部报错,也要缓存入一个默认值而不是直接异常上抛。(这里不无脑try/catche的原因是,对于部分业务来说,若cache返回emptyCollection/null的话,相当于脏数据会影响后续业务流程)
结语
通过对整起case的分析可以发现,其中任何一个因素其实都不是严重的bug点。然后在高并发场景下却会出现隐患,继而导致系统可用性降低这种C端系统严格禁止的情况。
这就对我们之后日常编码起到很好的警示作用,平时工作中还是要多读书多看报,在使用一个组件的时候尽可能的多看源码,也许就可以发现一些隐藏的风险点