Raft算法推导--《软件架构设计:大型网站技术架构与业务架构融合之道》
单点写入
Multi Paxos虽然可以选举一个leader但也不是强制执行,且本身也是允许多主存在的。
而为了简化这一问题,Raft算法规定必须要有Leader节点,且任意时刻只能有1个Leader节点,所有写请求都传到Leader上,然后Leader再同步给Follower。
这样一来,问题就简化成了客户端->Leader->Follower的一个顺序链路中。
整个算法的阶段也就清晰的分成了
阶段一:选举阶段,选举出一个Leader。
阶段二:正常阶段,Leader正常接受写请求,然后转发给Follower
阶段三:恢复阶段,旧Leader宕机,新Leader上任,由新Leader开始转发请求。
日志结构
在讲算法的三个阶段之前,需要先详细介绍日志的结构。因为复制的就是日志,日志的存储结构是这个算法的基石
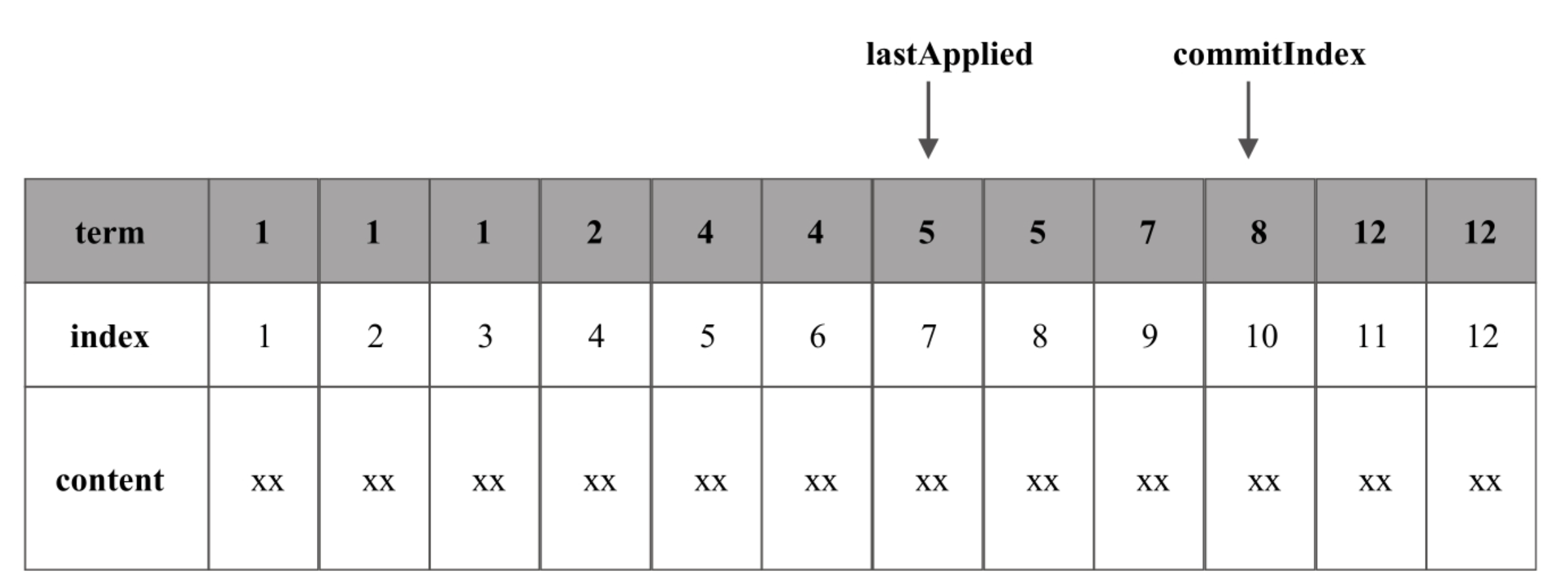
term与index
如图,每条日志都由term、index、content来组成,其中content就是日志内容,index为日志的顺序编号,类似于Kafka的offset。
term则是指写入日志的Leader的“任期”,即epoch。代表是自系统启动后的第几任Leader节点,单调递增的。
这里我们需要要求日志需要满足后一个index的term要>=前一个index的term。这是为了解决脑裂问题。
lastApplied与commitIndex
commitIndex的作用类似于Kafka的HW,即该index及其之前的日志被半数以上的follower接受。而一旦一条日志被commit,就认为该日志不能被改变和删除了。同时与Kafka相同在于,通过一个全局的commitIndex后,就不需要为每个index的日志去维护一个commit/uncommit的状态(只要<=commitIndex的都被认为是commit)。同时follower也不需要为每一个复制过来的日志逐条反馈给leader其对应的commit状态。
而由于Raft和Paxos一样,也是通过存储日志来保持对变量状态的维护,因此lastApplied自然就是表示当前日志序列中,哪些已经回放到状态机了。
state
理解了日志的结构,下面来看每个节点上都维护了哪些变量,这些变量一起构成了每个节点的State
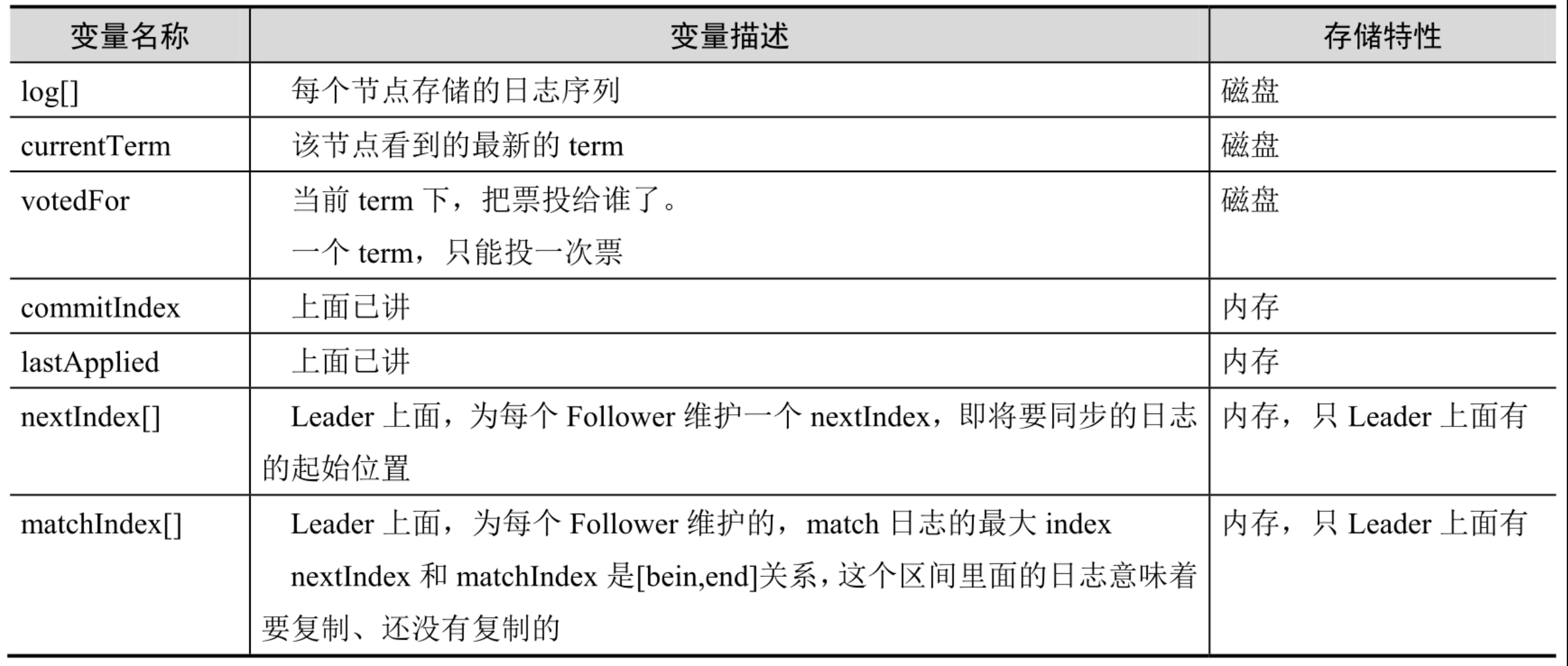
思考🤔为啥前三个需要落盘而后四个只需要存在内存中。
- log: 日志落盘,这个感觉没啥可说的,否则如果落内存那岂不重启就丢数据了
- currentTerm与voteFor:反证法证明,如果不落盘,对于currentTerm来说节点再启动时值为0,那么此时若收到脑裂的Leader节点的请求也会响应,集群不一致;对于voteFor来说节点再启动后值也为0,此时就可以又给别的节点选举投票,违背了一个节点只能voteFor一个节点的约定。
- 后四个:这四个都是针对leader节点生效,而一个节点如果宕机重启后大概率不再会是leader节点,因此也没必要落盘。
Leader选举
Raft算法里,Leader周期性的向所有follower发送心跳。如果follower在给定的时间内没收到Leader的心跳,则认为Leader宕机,然后会随机睡眠一段时间(为了避免同一时间所有节点参与选举),发起选举Leader操作。而对于Leader如果发现有更大term的Leader存在,则推位成follower。
这里,Raft的心跳是单向的,即只能Leader周期性的往follower发送心跳。与zab则是双向的。
leader选举实现过程
处于Candidate状态的节点会像所有节点发送一个RequestVote的RPC调用,如果超半数节点回复true,则该节点晋升为leader。RequestVote表现如下
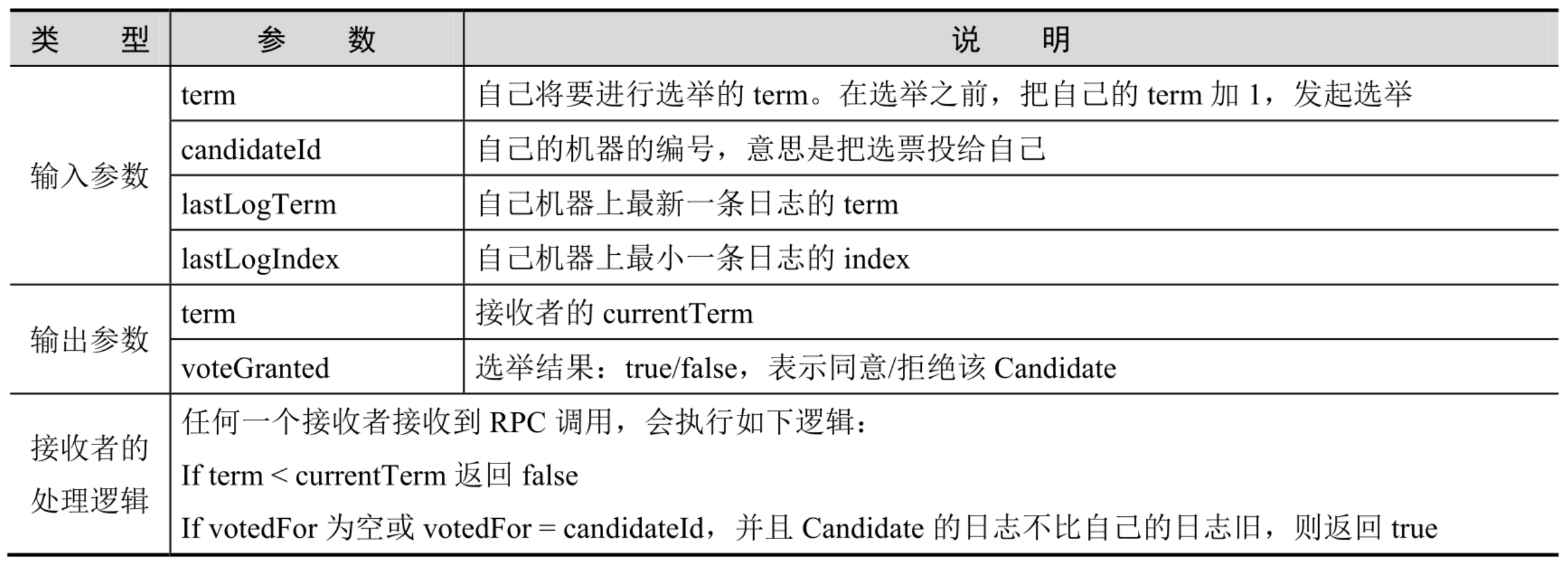
对于接收者处理逻辑里的日志的新旧判断,
- a.term > b.term
- a.term == b.term && a.index > b.index
选举过程中,若收到半数以上true则晋升为leader、若未收到则睡眠一段时间后重新发起选举请求、若选举中收到某个Leader节点的复制请求,且term>=自己这次选举的term,则承认其leader行为退位成follower,但如果term<自己本次的term,则拒绝该请求,继续发起选举。
日志复制
leader成功选举后,进入第二阶段复制阶段。leader会发起AppendEntries RPC调用,
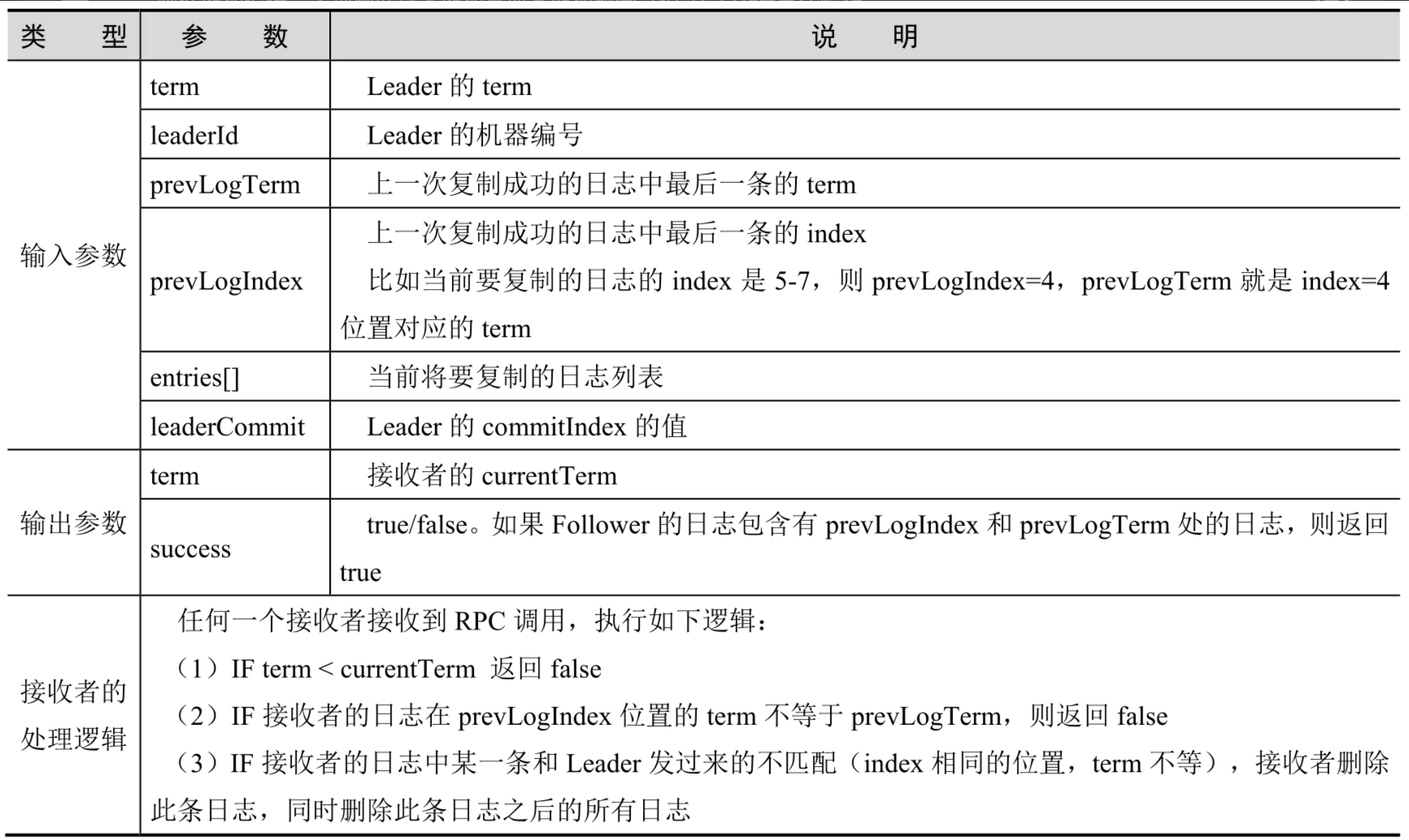

接收者通过1保证接受的就是Leader节点的值。
通过2保证该Leader节点的日志序列与上一次复制到的日志序列是同一份数据
通过3来完成日志的截断,虽然可能丢消息但集群还是一致的
通过4和5来完成日志的落地。